

Before relying on confidence scoring of LLMs in a setting of document review, there are certain thin...

Imagine you have a document review request, and want to find documents that are likely relevant to it. Here, we will ignore the process of actually training or prompting, and look at the one thing that’s often overlooked in the discussions about LLMs vs. our traditional first-generation TAR models – their output.
Below is an illustration of a simple request and a sample document. With a first-gen TAR model, like SVM or Logistic Regression (the two most commonly employed models in the TAR 1.0/2.0 workflows), your output is always a score (between 0 and 1 or a percentage). With an LLM-based model, it can get complicated. The most common use of an LLM in review-based products is to simply have the LLM provide a decision directly, e.g., Responsive vs. Not Responsive.

And here is where we run into our first main difference between first-gen TAR models and LLMs. When you run the same model (i.e., trained on the same set of documents and containing the same parameters) on the same document, you will always get the same exact answer:
 Now here is what would happen if you ran the same exact LLM model (e.g., GPT4), seconds apart, on the same exact document:
Now here is what would happen if you ran the same exact LLM model (e.g., GPT4), seconds apart, on the same exact document:

We’ve all already encountered that in our day-to-day use of LLM models – their answers may vary, even for the same prompt. But is that really a problem in document review? The fact that the above example shows that out of 3 runs, the model gives 1 inconsistent decision, may seem like an obvious problem – but bear with me, let’s play the devil’s advocate here and try to give LLMs a chance. After all, the first-gen model didn’t provide us with a decision – it only gave a confidence score, in which case the example above showed a 30% confidence in the document being responsive. Perhaps we are simply comparing apples to oranges – and the LLM’s inconsistency reflects the same uncertainty communicated by a first-gen LLM model via a score? The natural question is --- can’t we just get a score out of an LLM instead of a decision? And if we can – how? And would it be consistent and repeatable, like the scores we get out of our trusty old first-generation TAR models?
How to get scores from LLMs?
Before we answer that question, we have to first see how we get scores out of our first-generation TAR models. We don’t have to go deep into the bowels of these models to see how that happens – all that we have to remember is that concept of a mathematical function that we learned in middle school – we put in a number x and get out a number y, be that function a line, a parabola, or in the case of LLMs and even first-generation TAR models, something a bit more complicated. It doesn’t matter what the function is – you’ll probably remember that any function would always give the same output for the same input.
That’s exactly what happens inside a first-generation LLM model. It just takes your document, encoded as a set of numbers, and chugs it into a function, which spits out another number – the number that we call the confidence score:

Easy enough. Then what’s so different inside an LLM? Why isn’t its output consistent?
LLMs, as powerful as they are, underneath aren’t very different. They also contain a function that takes in an input and provides an output – a more complex function, but still a function, and therefore for every input must generate a consistent output. Then what gives?
The main difference is that LLMs sample. They flip a coin based on the output score of its internal function – a function that’s hidden from view:

The obvious question then is – well, can we please get that score, since it exists? After all, if it exists, it should be possible to get…right? 
Yes – in theory you could get that score. The problem is – it doesn’t actually mean what we may think it means. If an LLM is asked to categorize a document into say Responsive and Not Responsive, its internal scores do NOT inherently represent the model’s confidence in the ultimate decision it gives you.
But why is that? Didn’t we just say that both models ultimately compute a function that produces a score? That’s right, but there is a caveat that’s often overlooked – the key nuance is that the score represents something different altogether in both models, first-gen TAR and LLMs – the score in both models represents the confidence of a model at a task its trained to perform. The keyword is trained, and here is why:
- A first-gen model is trained to perform one task – to classify responsiveness of a document, and therefore its score becomes a surrogate for responsiveness.
- An LLM model is trained at the “factory” to generate words in response to a request. Its task is to generate natural language sentences.
And that’s precisely what an LLM does when you ask it to categorize a document:

Its internal functions will be generating scores for each word in its response sentence, flipping a coin each time to produce an actual word, one at a time.
So if the internal score of an LLM doesn’t represent confidence in its responsiveness call, what does it mean then?
If you apply the principle that I outlined earlier – all models generate scores to reflect its confidence in the task it was trained to do – the answer becomes self-evident: LLM scores, even if accessible, represent the confidence in having generated that particular sentence, i.e., that particular sequence of words. After all, if it’s flipping a coin every time it spits out a word, there is always a chance it could have generated a different word, and therefore a slightly different sentence. The response might mean exactly the same thing, but the sentence might be worded differently.
In other words --- LLMs internal scores, even if accessible, are of limited use – they do NOT encode the confidence in the decision you asked it to make it in a prompt.

OK, but if LLMs just answer questions in response to a prompt, then next obvious question is:
Can’t we just nicely ask LLM for a score?
Yes – what if we just asked? In fact, that is the approach we see commonly taken by solution providers that rely on external LLMs, like GPT4, to perform document review. Since those models do not provide access to their scores anyway, that really becomes the only option.
For example, a slight alteration to the original prompt, might look like this:

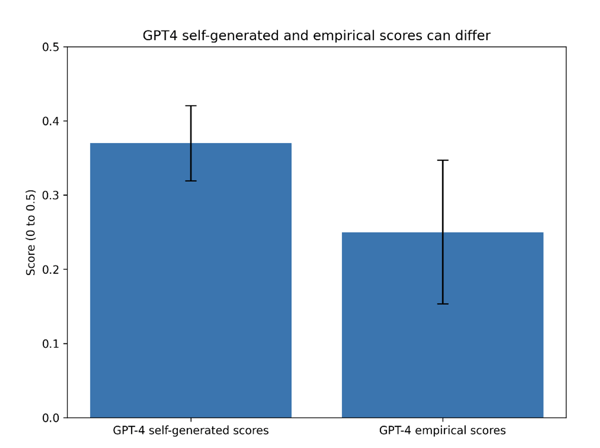
This is what we call a “generated score” or a self-generated score. Before you read any further, or look at the next figure, try to see what issues might arise with this approach. 
That’s right – after all, given that we now how LLMs generate all its output, why would asking it for a numerical score be any different? Since it’s flipping a coin on every single word it’s producing in its response and it isn’t treating numbers any different than just words (or tokens to be more precise), its output generated confidence, would too differ from request to request, EVEN if nothing changes to your prompt or input document.
Now a reasonable question is the same as the one we started with in this article – does it matter that it isn’t consistent in its response? What implication would this have on the TAR workflow as a whole, if we were to rely on such variable output? The implications are quite significant, and in some ways non-obvious. But before we even discuss that, we haven’t yet exhausted all the ways in which we could try to get consistent confidence scoring out of LLMs. There is one more way.
Can’t we just ask again.. and again.. and again?
Go back to statistics and probability 101. I remember doing this experiment in 7th grade. Our teacher actually asked us to flip coins for 20 minutes, and then estimate the likelihood of a coin flipping heads (or tails). Can’t we use the same principle here to get confidence estimates out of an LLM?
Let’s come back to our trusty old first-generation TAR model. Recall that it provides us with consistent estimates of its confidence. It’s repeatable, asked again and again on the same document, it will give the same answer:
But what if it didn’t? What it operated the same way an LLM does? What if it flipped a coin every time it provided a decision, instead of giving a score? 
Well, if its confidence score was say 0.3, and it flipped a coin with a probability 30% each time, then over 10 different flips, you would expect about a third to be a Responsive decision. That’s just basic probability. Obviously, this exercise is pointless for a first-generation TAR model since it gives you a score to begin with, and estimating it on repeated experiments is pointless. But it isn’t so pointless for an LLM model, where its true confidence is entirely unknown (and isn’t even encoded in its internal score parameter, as we established earlier).
So here is an idea – what if we asked the same question of an LLM ten times, keeping track of decisions:

Would the proportion of Responsive calls to the total number of experiments, represent the model’s true confidence in its decision?
The answer to that question is a resounding YES. That actually is the correct way to establish anything unknown from a fixed statistical distribution (which an LLM model certain is, unless its version changes in the middle of the experiment – but more on that later). But there are two problems with this empirical estimation of a confidence score, one an obvious one, and one slightly more technical:
- It’s expensive! Calling an external model like GPT4, again and again, on the same document is highly wasteful, and time-consuming.
- It doesn’t entirely get rid of uncertainty around the confidence score. Like all empirical estimation, the range of the estimate’s uncertainty will depend on the number of samples. For example, performing the experiment 10 times, only narrows down the confidence to a range between 0.4 and 0.6 (assuming the true confidence score was 0.5). Does it matter? We will see in the next article.
Well, if its confidence score was say 0.3, and it flipped a coin with a probability 30% each time, then over 10 different flips, you would expect about a third to be a Responsive decision. That’s just basic probability. Obviously, this exercise is pointless for a first-generation TAR model since it gives you a score to begin with, and estimating it on repeated experiments is pointless. But it isn’t so pointless for an LLM model, where its true confidence is entirely unknown (and isn’t even encoded in its internal score parameter, as we established earlier).

